
LoRA+: Efficient Low Rank Adaptation of Large Models
An intuitive explanation of LoRA+ for practitioners

In this article, I will explain the main idea behind LoRA+ (Efficient Low-Rank Adaptation of Large Models). I decided to write this post especially for practitioners who might find the mathematical formulations in the original paper challenging to comprehend (and thus might be discouraged from reading the paper). The goal of this article is to provide a simple and intuitive explanation of LoRA+, introduced in our paper "LoRA+: Efficient Low Rank Adaptation of Large Models" (special thanks to my co-authors Nikhil Ghosh and Bin Yu).
1. LoRA (Hu et al. (2021))
Let us first start with the definition of Low-Rank Adaptation (LoRA), introduced in Hu et al. (2021). In essence, LoRA works by adding low-rank adapters to the pre-trained weights. Consider a general pre-trained model of the form
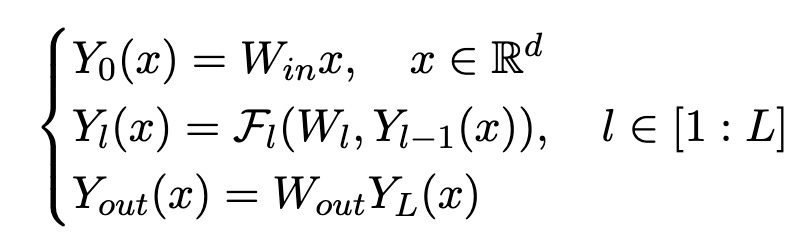
Assuming that some weight matrix W in the pre-trained model is (for instance) of size n x n, LoRA finetuning considers the following reparametrization of the weights

With this parametrization, the matrix BA is of rank r which is generally much smaller than the dimensions of W (hence the name “Low Rank’’). During LoRA finetuning, only matrices A and B are trained and pre-trained weights W remain fixed. This effectively reduces the number of trainable parameters from n x n to 2nr , which significantly reduces the computational cost if r is much smaller than n. In the next section, we explain why current LoRA finetuning routine is suboptimal and introduce LoRA+ to mitigate the issue.
2. LoRA+ (Hayou et al. (2024))
In practice, LoRA modules A and B are trained with AdamW (standard optimizer) following the rule

where the matrices G are processed gradients (effective update matrices we get after processing the original gradients) which have entries of order 1 (do not go to zero or grow with embedding dimension n because of the normalization in AdamW). With this rule, for a finite number of steps T, the updates in A and B are proportional to the learning rate η. Now, the key idea is to look at the change in preactivations (embeddings) when the rank r is small and the embedding dimension n (model width) is large.
The matrix A is involved in computations of the form Az for some vector of dimension n. To stabilize these computations when the embedding dimension n is large (a typical scenario in practice), one should scale the learning rate with width n, and the optimal scaling in this case is 1/n. To see why this is the case, let’s look at how the updates in A affect stability and learning. After T steps, the change in A is given by

where the sum is over T steps. All the matrices inside the sum are of dimension r by n which means that the sum itself is of dimension r by n. After the updates, the matrix ∆A is involved in computations of the form ∆Az for some vector z of dimension n (preactivations before LoRA layer). Assuming that z has entries of order 1 in width (this relates to stability from pre-training), and since the matrices G have entries of order 1 (with respect to dimension n) because of the normalization from AdamW, we should expect that ∆Az has entries of order η × n, which yields to the conclusion that η should scale as 1/n.
On the contrary, the matrix B will always be involved in computations of the form Bz for some vector z of dimension r (not n!). A similar reasoning yields that the optimal learning rate for B should scale as 1/r (or basically order 1 with respect to n since r is typically very small, e.g. r=4 or 8).

This analysis shows that using the same learning rate for A and B is suboptimal as the two modules require different orders of magnitudes for the optimal learning rate. Typically, the optimal choice of learning rates should satisfy η(B) ≫ η(A) (where η(X) refers to the learning rate used to train some matrix X).

To confirm this intuition, we conduct large scale finetuning experiments where we used different learning rates for A and B.
2.1 GLUE tasks with RoBERTa:

The figure above shows the results of low rank adaptation of Roberta-base model for different learning rates for A and B modules on some of the GLUE tasks. The results support the our theoretical analysis, showing that optimal choice of learning rates satsifies η(B) ≫ η(A). See the paper for more empirical results.
2.2 Exps with LLama-7B:

The figure above shows the results of finetuning of LLama-7b for two tasks MMLU (finetuned on flan-v2) and MNLI (finetuned on MNLI). For MMLU, the conclusion from previous RoBERTa results still holds with optimal learning rates satisfying η(B) ≫ η(A). However, for MNLI, it seems that choosing significantly larger learning rate for B (compared to A) hurts performance. An explanation for this effect is that MNLI is too easy for LLama-7b, and efficient finetuning in this case leads to overfitting. From this, we conclude that:
When the task is “hard enough” for the pretrained model, the learning rates should be set such that η(B) ≫ η(A) !!
However, this analysis only suggests that η(B) ≫ η(A) and in practice one cannot tune both η(B) and η(A) using grid search as this will become a (expensive) 2D tuning problem. One solution is to set a fixed ratio λ between the learning rates, i.e.:
and tune only η(A). We call this method LoRA+ (see below for guidelines on the choice of λ).
2.2 How to use LoRA+?
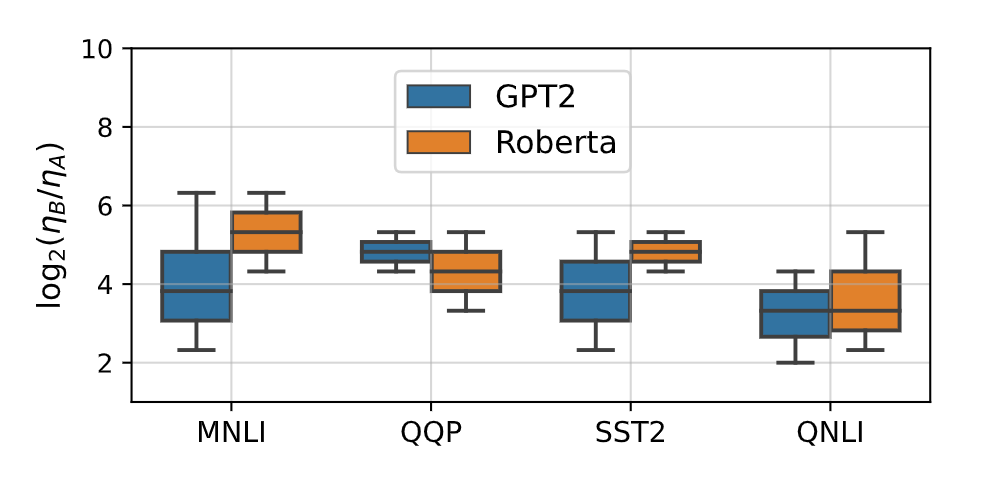
To determine the optimal ratio λ (in terms of test loss), we show the distribution of the (empirically) best 4 choices of the learning rates from a 2D grid search, for different tasks and models. As expected, the optimal ratio λ depends both on the model and the finetuning task. However, we found that empirically choosing λ≈2^4 generally yields improves performance (compared to using the same LR for A and B, i.e. standard LoRA). As a rule of thumb, we recommend choosing a ratio λ between 2^3 and 2^5 as a first choice. However, adding to our analysis in the previous section note that the gain from LoRA+ is most noticeable when the task is “hard enough” for the pretrained model!
Also, we found that initializing B to random and A to zero yields better results with LoRA+ in general (in constrast, in LoRA paper, A is initialized to random and B to zero).
Paper: https://arxiv.org/abs/2402.12354
Code: https://github.com/nikhil-ghosh-berkeley/loraplus
References:
1. “LoRA+: Low Rank Adaptation of Large Models” (2024). Soufiane Hayou*, Nikhil Ghosh*, Bin Yu.
2. “LoRA: Low-Rank Adaptation of Large Language Models”. Hu et al. (2021)